LeGo-LOAM+单目相机
本节记录使用相机去辅助LeGo-LOAM,代码主要来自VINS-Mono与LeGo-LOAM,相机主要用在两个方面:1、与激光紧耦合去估计位姿;2、进行视觉回环检测。
多传感器融合定位方案中传感器选择的过程就是寻找互补性的过程,融合的过程就是执行互补的过程。具体来讲,IMU和GNSS融合定位,IMU有累计误差但是没有位姿跳变,GNSS没有累计误差但是信号受到干扰或者遮挡时会跳变。二者融合,既能消除累计误差又能避免位姿跳变,可以表述为,误差在累积性和噪声性上都有互补。
单纯基于激光点云的里程计算法,只能利用环境的几何结构信息来提取特征点,这会导致在一些场景下产生约束退化的问题:
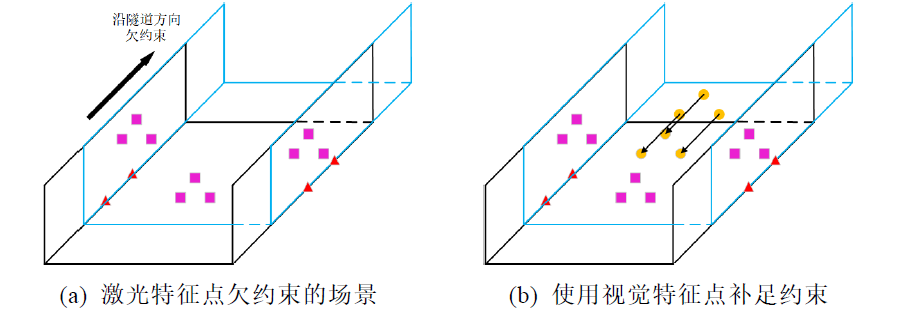
视觉特征点提取的是环境中的图像纹理信息,其和只能表达环境几何结构信息的激光特征点有天然的互补性。
以下视觉与Lidar融合的方法主要参考LIMO。
1、视觉特征点的提取
视觉特征点采用光流跟踪的方式提取,这一点可以直接利用VINS-Mono中的feature_tracker节点,其可以生成均匀分布的视觉特征点。这部分代码是VINS代码中相对简单的,不太需要解释。
2、深度恢复
这里通过对时间对齐的一帧点云与视觉特征点进行数据关联来恢复视觉特征点的深度。相对于多帧点云来恢复视觉特征点的深度,仅使用一帧点云来计算虽然有点云比较稀疏的缺点,但是也避免了对帧间运动的依赖。
视觉特征点与激光雷达的点云都统一到相机的归一化平面处理:

这里的激光雷达点云是经过LeGo-LOAM中物体分割处理后的,每一个激光点都带有一个标签。数据关联是使用视觉特征点(红色的点)周围的激光点(白色的点)去恢复视觉特征点的3D深度,这一周围的邻域是使用蓝色的框表示的。为了确保邻域点能拟合出平面参数,这个蓝色的方格大小需要保证在每一方向上至少包含两条激光线。之后的处理步骤:
2.1、将点云分发到每一视觉特征点的包围盒内;
2.2、对于每一视觉特征点包围盒内的点云按照类别分类;
2.3、选取分类好的cluster中最前景的cluster点集(上图中的黄色点就是这部分点);
通常情况下视觉特征点位于环境中的边线和边角位置,因此其近邻点集通常包含了前景物体和后景物体上的激光点,直接使用近邻点集进行深度估计可能得到错误的深度恢复。
2.4、从满足条件的cluster点集中选取组成三角形面积最大的三个点进行平面恢复;
三角形面积还需大于一定的阈值,因为有可能三个点都在一条scan上,上图中就出现了这个情况。假设平面不过原点,用三个点就可以拟合出来一张平面$Ax+By+cz+1 = 0$。直接写成矩阵用线性代数的知识就能求解了,若是超定方程可以使用一次最小二乘$(A^TA)^{-1}A^Tb$。刚好最近看了多视图几何,这本书中的解法如下:

接下来使用这个平面去估计视觉特征点的深度,注意构造这个平面用的是投影到相机坐标系下的激光点。相机光心与视觉特征点连成的射线与拟合平面的交点作为视觉特征点在相机坐标系下的深度。射线与平面的交点如下求解:
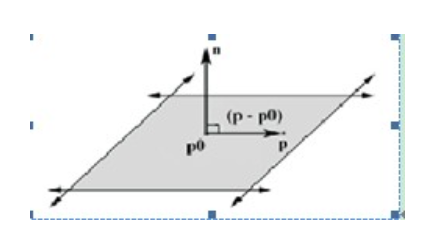
平面的表示方法:
$$
n^Tp+d = 0
$$
其中$p$是平面上任意一个点,另外射线可以表示为一个起点加一个方向:
$$
p(t) = p_0 + tu
$$
交点即在平面上又在射线上,则有:
$$
\begin{aligned}
&n^T(p_0+tu)+d = 0 \\
&t = \frac{-(d+n^Tp_0)}{n^Tu}
\end{aligned}
$$
如此交点便可以求取。一个更直接的公式是:
$$
X_{3d}^{C} = |\frac{d}{n^TX_{2d}^C}|X_{2d}^C
$$
其中$X_{2d}^C$是归一化相机平面的视觉特征点,$X_{3d}^C$是深度恢复的相机坐标系下的视觉特征点。
2.5、深度验证
前述步骤得到的有效深度估计必须满足一下两点:
- 当前视觉特征点的射线与拟合平面的法线夹角小于设定阈值15°,否则深度估计结果噪声太大;
- 深度恢复出的视觉特征点距离相机光心小于设定阈值30m,距离太大点云比较稀疏,近邻点集包含的点尺度范围太大,进而导致平面拟合不准确。
3、激光视觉紧耦合
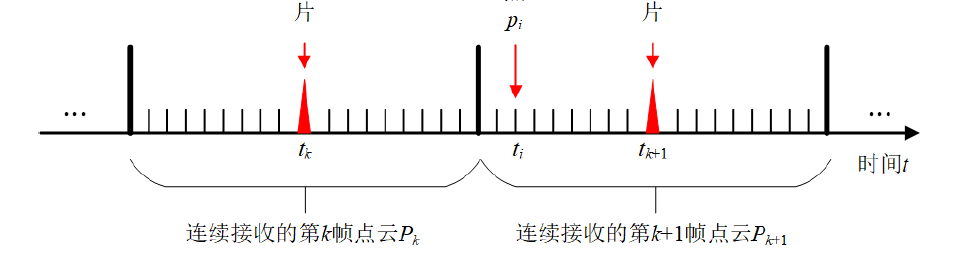
LeGo-LOAM中实际估计的是当前帧点云结束点时刻的Lidar坐标系到上一帧点云结束点时刻Lidar坐标系的变换$T_{cur-end}^{last-end}$。本方法要求相机与Lidar的频率一致,相机的采样时刻在一帧点云中。本帧视觉特征点与上一帧的视觉特征点通过特征点的ID建立匹配关系,这样可以建立如下的距离约束:
$$
\begin{aligned}
T_{k+1}^{k} &= \frac{t_{k+1} - t_{k}}{ScanPeriod}T_{cur-end}^{last-end} \\
d &= | p^k - T_{k+1}^{k}p^{k+1}|
\end{aligned}
$$
其中$t_{k+1}$表示当前图像帧的时间戳,$t_k$表示上一帧图像的时间戳,$p^{k+1}$表示当前帧的一个视觉特征点,$p^k$表示的是上一帧中与$p^{k+1}$同一ID的匹配点。
由此可建立视觉特征点之间的距离约束,之后与LeGo-LOAM中边线特征点构成的点到直线的距离约束、平面特征点构成的点到平面的距离约束一同送入优化函数,实现紧耦合联合优化。

